2. 판다스, 시각화_영화 추천 모델
# Kaggle Data로 Test 예정.
1. EDA (Exploratory Data Analysis)
1) 정의 :
- raw data에 대한 다각도 관찰을 통한 이해
- 데이터 분석 전, 그래프나 통계적 방법으로 자료 직관적으로 바라보는 과정
2) 필요한 이유 :
- 데이터 잠재적 문제 발견
- 데이터 패턴 확인을 통한 기존 가설 수정, 혹은 새로운 가설 수립
3) 과정 :
- 분석 목적과 변수 확인 (개별 변수의 이름 및 설명)
- 데이터 이상치, 결측치 확인
- 데이터의 개별 속성값
- 속성 간의 관계 (상관관계, 시각화)
2. 데이터 결측치 확인 및 시각화
import pandas as pd
2.1.1 첫 행이 header가 아닌 경우
'df 이름' = pd.read.csv('경로/파일명.csv', header=None)
# 첫 행을 지우기
'df 이름'.drop(index=0, inplace=True)
# 열 이름 정하기
'df 이름'.columns = ['A', 'B', 'C']- inplace=True 는 해당 결과를 df에 재할당 의미
2.1.2 첫 행이 header인 경우
pd.read_csv('경로/파일명.csv', header = 0)
2.2 데이터 구조 확인
# 행렬 구조
"df 이름".shape
# 데이터 타입
"df 이름".dtypes
# 결측치 개수 확인
"df 이름".isnull().sum()
2.3 데이터 시각화
import matplotlib.pyplot as plt
# 이상치 시각화
plt.boxplot('df 이름'.drop(index=0) # header=None으로 컬럼명이 행의 첫 줄로 가 있어서 index=0
.astype({'C':'int'})['C']) # 컬럼 c에 해당하는 부분을 int로 바꾸고 boxplot 확인
plt.show()
# header 이미 지정된 경우
plt.boxplot('df 이름'.astype({'C':'int'})['C'])
3. 데이터 전처리
import pandas as pd
3.1 df 전체 속성 변경
'df 이름' = 'df 이름'.astype('int')
3.2 시청시간에 따라 시청 여부 분류
# 시청시간이 10분 미만이면 0으로 변경 (시청하지 않음을 의미)
'df 이름'.loc['df 이름'.DURATION<10, 'DURATION']=0
# 나머지는 1로 변경 (시청함을 의미)
'df 이름'.loc['df 이름'.DURATION>0, 'DURATION']=1
3.3 필요 없는 컬럼 삭제
# 문제 정보, 영화 정보에서 필요 없는 내용들을 제외함
df_question.drop('시청일', axis=1, inplace=True)
df_questin.drop('시청횟수', axis=1, inplace=True)
df_movie.drop('RELEASE_MONTH', axis=1, inplace=True)- 'df 영화' : 'MOVIE_ID', 'TITLE'
- 'df 문제' : 'USER_ID', 'MOVIE_ID', 'DURATION'
3.4 데이터 프레임 합치기 (concat, merge, join)
user_movie_data = pd.merge(df_question,df_movie,on="MOVIE_ID")
3.5 rating(Duration) 기준으로 User-Movie Matrix 만들기
import numpy as np
from tqdm import tqdm # 진척도 표시
# columns는 영화의 'TITLE', index는 'USER_ID'로 설정. 이때 unique 메소드로 중복값 처리
user_movie_rating = pd.DataFrame(0, columns=user_movie_data["TITLE"].unique(),
index=user_movie_data["USER_ID"].unique())
for i in tqdm(range(user_movie_data.shape[0])):
# i번째 줄의 USER_ID 가져오기
cur_user_id = user_movie_data.iloc[i]['USER_ID']
# i번째 줄의 TITLE 가져오기
cur_movie_title = user_movie_data.iloc[i]['TITLE']
# i번째 줄의 DURATION 가져와서 user_movie_rating 행렬에 저장하기
user_movie_rating.loc[cur_user_id, cur_movie_title] = user_movie_data.iloc[i]['DURATION']
# user_movie_rating의 index를 USER_ID 기준으로 정렬
user_movie_rating.sort_index(axis=0, inplace=True)
4. 추천 알고리즘 적용
- 콘텐츠 기반 필터링 (Content based filtering)
1) 개념 : 기존 시청 데이터와 유사 콘텐츠 추천 (감독, 배우, 장르, 키워드 등 - 과거 자주 사용)
- 협업 필터링 (Collaborative filtering)
1) 개념 : 기호가 비슷한 유저의 데이터 기반 추천
2) 단점 :
- Cold Start Problem : 기존과 관련 없는 새로운 콘텐츠 추천 불가
- Long Tail : 관심 많은 콘텐츠만 추천 (비대칭적 쏠림 현상)
- 계산 효율 저하

- 잠재 요인 협업 필터링 (Latent factor based collaborative filtering) - Matrix factorization

4.1 SVD (Singular Value Decomposition. 특이값 분해)
1) 개념 : 차원 축소 기법 중 하나로, U, Σ. V 각 행렬에서 중요도 높은 t개만큼만 사용
2) 장점 :
- cost effective
- noise 저하


4.2 SVD 활용을 위한 전처리
from sklearn.decomposition import TruncatedSVD
from scipy.sparse.linalg import svds
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# user_movie_rating을 transpose하여 movie_user_rating 행렬로 변경
movie_user_rating = user_movie_rating.T
# movie_user_rating 행렬을 numpy 형태 행렬로 변경
movie_user_rating = movie_user_rating.to_numpy()
4.3 Truncated SVD
# 상위 15개를 이용한 Truncated SVD를 사용하여 movie_user_rating 행렬을 분해하고 행렬 shape 확인
SVD = TruncatedSVD(n_components=15)
matrix = SVD.fit_transform(movie_user_rating)
matrix.shape
4.4 피어슨 상관계수 확인
# 행렬의 coefficent를 가지고 correlation을 구함
corr = np.corrcoef(matrix)# correlation에서 20개만으로 heatmap을 그림
corr2 = corr[:20, :20]
plt.figure(figsize=(16, 10))
sns.heatmap(corr2)
# correlation에서 200개로 heatmap을 그림
corr2 = corr[:200, :200]
plt.figure(figsize=(16, 10))
sns.heatmap(corr2)
4.5 유사 영화 리스트 추출
# 영화 제목을 넣어서 그 영화의 coefficient를 계산
movie_title = user_movie_rating.columns # 영화 제목 주출
movie_title_list = list(movie_title) # 영화 제목 리스트 생성
coffey_hands = movie_title_list.index('히든피겨스') # Query 영화 선택
# 계산된 coefficient 값을 기반으로 가장 비슷한 영화를 골라냄 (item-based cf or content-based filtering)
corr_coffey_hands = corr[coffey_hands]
list(movie_title[(corr_coffey_hands >= 0.85)])[:50] #50개 영화 추출
# 계산된 coefficient 값을 기반으로 가장 비슷한 영화를 골라냄 (item-based cf or content-based filtering)
corr_coffey_hands = corr[coffey_hands]
list(movie_title[(corr_coffey_hands >= 0.9)])[:50] # 50개 영화 추출
5. 모델 평가 방법
5.1 Confusion matrix
- 추천 O 정답 O : TP
- 추천 O 정답 X : FP
- 추천 X 정답 O : FN
- 추천 X 정답 X : TN
5.2 평가지표
- Accuracy : (TP+TN) / Total
- Recall : TP / (TP+FN)
- Precision : TP / (TP+FP)
- F1 measure : Precision & Recall 조화 평균
→ F1 = (2Precision x Recall) / {Precision + Recall)
- mAP : Precision의 Mean값

- nDCG (normalized Discounted Cumulative Gain) : 랭킹 기반 추천 시스템에 사용되는 평가 지표.
→ 어떤 순서로 추천할 것인가 고려. 검색엔진 / 추천 시스템 평가 등 다양하게 사용
5.3 CG (Cumulative Gain)
1) 개념 : 상위 p개의 추천 결과들의 관련성 (rel. relevance)을 합한 누적 값
→ rel은 관련 있으면 1, 없으면 0과 같이 binary value로도 사용 가능
2) 단점 : 상위 p개의 추천 결과들을 동일 비중으로 계산하며, 순서 고려 X

5.4 DCG (Discounted Cumulative Gain)
1) 개념 : CG값에 랭킹 순서에 따라 점점 비중을 줄여서 관련도 계산.
2) 단점 : p가 커질수록 DCG 값이 커짐

5.5 nDCG (normalized Discounted Cumulative Gain)
- p의 길이에 상관없이 일정 스케일 가지도록 normalization

5.6 ED (Entropy Diversity)
- 한 집단 내 데이터에 얼마나 다양한 class가 균등하게(편중되지 않게 존재하는지)
Ex) 추천한 리스트에 얼마나 다양한 영화 장르가 골고루 있는가

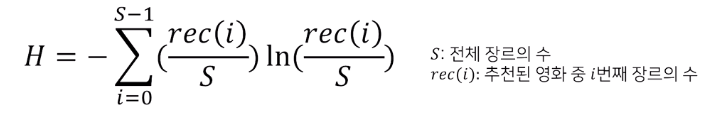
5.7 etc
- RMSE : 실제와 가정에 대해 Error 가 적은 정도
- Serendipity : Relevant & Unexcpected 에 대한 평가


| 평가 지표 | 장점 | 단점 |
| Accuracy | 직관적 성능 보여줌 | 데이터 불균형성 고려 X |
| Precision | 추천하는 상품의 정답률 | 추천 시스템이 매우 보수적이게 됨 |
| Recall | 반드시 찾아내야 하는 상품 찾아줌 | 추천 시스템 추천 중 오류 증가 |
| mAP | Precision과 같음 | Precision과 같음 |
| nDCG | 순서 고려하여 추천 | 정해진 K개의 추천을 해야하나 그보다 적게 추천하는 경우에 대한 처리 필요 |
| ED | 추천 결과가 bias 되는 것 방지 | 추천 만족도 떨어질 수 있음 |
| Serendipity | 추천의 다양상, 만족도 높일 수 있음 | Unexpectedness, relevance 등의 consensus 필요 |
6. 알고리즘 최적화 (Loss 최소화)
- 주어진 데이터 기반 한번도 보지 못한 데이터 예측하는 모델
→ 주어진 데이터에 너무 정확히 들어맞는 모델 = overfitting
6.1 데이터셋 조정 (k fold Cross Validation)
- Data를 k개로 나누어, 돌아가며 test data로 사용 후 평균
6.2 알고리즘 변경 (Hybrid filtering - Collaboration + Content-based filtering)
6.3 평가지표 개선
- Gradient Decent
1) 개념 : 미분해서 0이 되는 지점
2) 단점 : Optimal solution을 찾지 않는 Greedy한 방법으로 Traing cost가 큰 편임
- Alternating Least Square
1) 개념 : 변수 하나를 고정하고 나머지 변수에 대한 최적값 빠르게 도출
